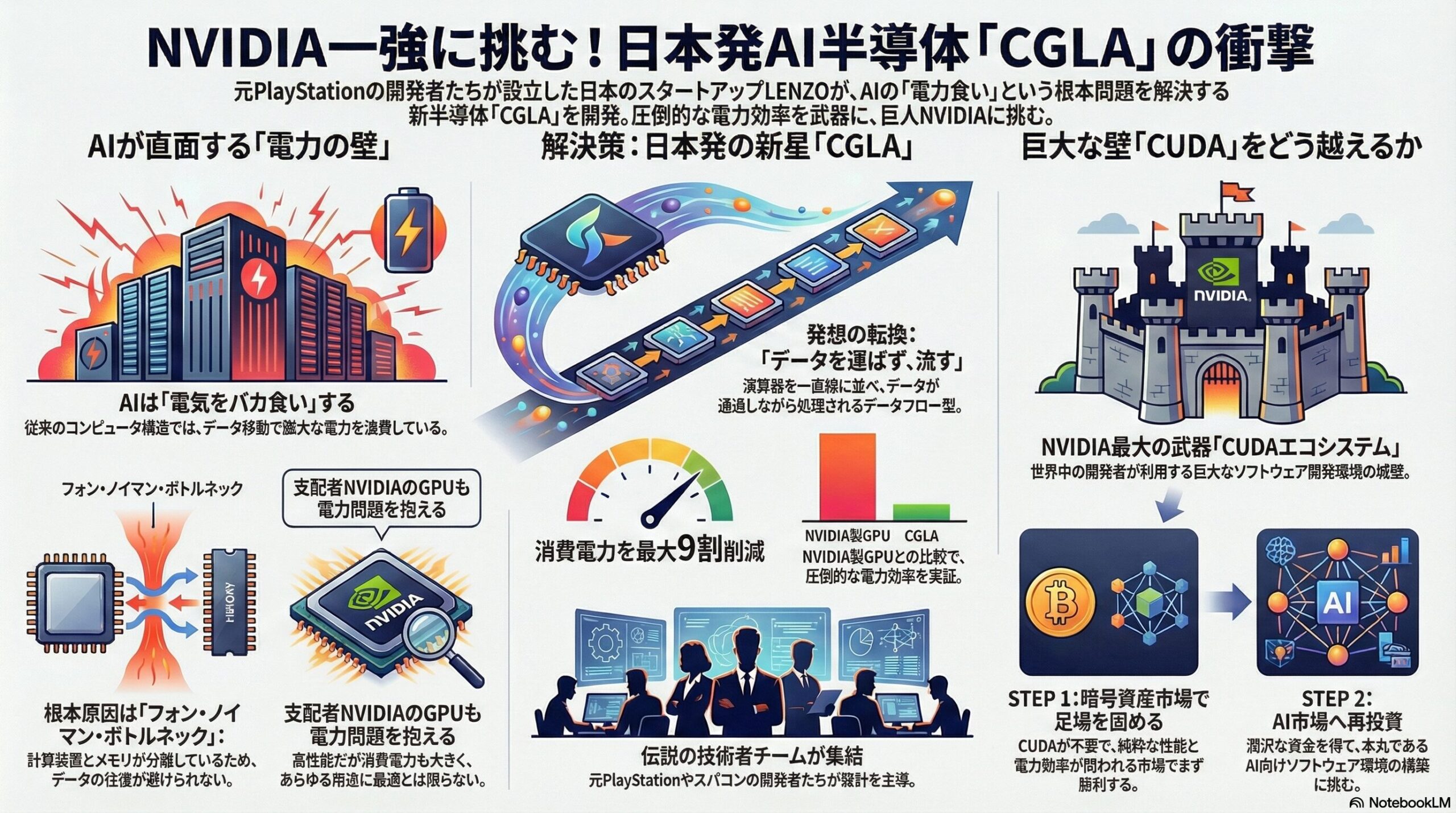
現在、世界のAIインフラはNVIDIAのGPUによって支えられていますが、そこには「電力消費」という限界が近づいています。AIモデルの学習や推論には膨大なデータの読み書きが必要であり、データセンターの電力需要は急激に増大し続けています。この「AIは便利だがエネルギーを食いすぎる」という矛盾に風穴を開けるべく立ち上がったのが、奈良先端科学技術大学院大学(NAIST)発のスタートアップ、**LENZO(レンゾ)**です。
1. 伝説の「プレステ開発陣」が再集結
LENZOを率いるのは、かつて世界を席巻したPlayStation 2や3の心臓部を開発した伝説のエンジニア、藤原健真氏です。さらに、日本のスーパーコンピュータ開発を牽引してきた権威、中島康彦教授がチーフアーキテクトとして参画しています。かつて世界一を経験した「匠」たちが、既存の汎用アーキテクチャの限界を打破するためにゼロから設計したのが、新アーキテクチャ**「CGLA(Coarse-Grained Linear Array)」**なのです。
2. 「フォン・ノイマンの壁」を打ち破るCGLAの正体
現代のコンピュータは、計算を行うプロセッサとデータを保存するメモリが分離された「フォン・ノイマン型」に基づいています。AI処理ではこの間をデータが往復する際に多くの時間と電力を浪費しますが、これを**「フォン・ノイマン・ボトルネック」**と呼びます。
CGLAはこの前提を覆し、データをメモリから「取りに行く」のではなく、演算器を一直線に並べてデータを効率的に「流し込む」データフロー指向の設計を採用しています。
• 自己更新データ方式: 演算ユニット(PE)自身が次に必要なデータを自律的に更新し、ホストPCとの通信ボトルネックを排除します。
• 拡張可能な線形PEアレイ: シンプルな一次元の線形構造により、設計が容易で、性能のスケールアップも容易です。
• 専用ALU設計: 特定のタスクに最適化され、1クロックで複数の演算を実行可能です。
この設計により、NVIDIAのハイエンドGPUと比較して**最大9割もの電力削減(1/10)**という、驚異的な電力効率を実現しました。
3. 「Crypto First」戦略:Cellの教訓から学んだ勝ち筋
いかにハードウェアが優れていても、NVIDIAが築き上げた強力なソフトウェアエコシステム「CUDA」の壁は高く、容易には崩せません。藤原氏は、かつてPS3のCellで「高性能だがプログラミングが困難で普及に苦戦した」という苦い教訓を深く認識しています。
そこでLENZOが取ったのが、極めて合理的な**「Crypto First(クリプト・ファースト)」戦略です。まず、CUDAのような複雑なソフトウェア資産に依存せず、純粋な計算性能と電力効率が収益に直結する暗号資産マイニング市場**で技術を実証し、軍資金を確保します。実際、7nmプロセスのCGLAは、より微細な5nmプロセスを採用する他社の最新鋭ASICを約2.6倍の性能で圧倒するベンチマークを叩き出しています。
ここで得た利益を、最大の難関であるAI向けソフトウェア環境の構築に再投資し、満を持してAI推論市場へと進出する二段階のシナリオを描いています。
4. 日本発、半導体復権への期待
CGLAは単なる「速いチップ」ではなく、AIが“電気を食う怪物”のままでいいのかという問いを突きつける技術です。消費電力が低いことは発熱の抑制にも繋がり、スマホや自動車、ロボットといった私たちの身近なデバイスで高度なAIを動かす**「エッジAI」**の普及を加速させる可能性を秘めています。
かつて世界の子供たちを熱狂させた技術者たちが、今度は「電力効率」という武器を携え、世界王者NVIDIAに挑む。この挑戦は、失われた30年を取り戻し、再び「日の丸半導体」が世界を驚かせる日の幕開けになるかもしれません。


コメント